

-

超大规模组网
需支持千卡级、万卡级GPU集群互联,采用CLOS架构实现弹性可扩展能力。
-

高带宽设计
大模型训练网络带宽向200G、400G、800G不断演进,满足GPU集群海量参数的协同计算。
-

低时延保障
绕过CPU、OS内核、TCP/IP协议栈等,直接访问对端内存数据,大幅降低通信延迟。
-

智能无损传输
接入层1:1带宽收敛比,利用RMDA、负载均衡技术保证全网智能控制拥塞及吞吐效率。

随着AIGC时代的到来,大模型训练参数规模从十亿、百亿不断向千亿、万亿跃迁(如GPT-4约有1.8万亿参数),传统网络架构正面临传输带宽不足、延迟过高、易丢失数据、链路负载不均、扩展性差等严峻挑战,无法满足当前千卡乃至万卡GPU集群的高并发通信需求。华讯AI智算网络解决方案旨在构建具备超大规模组网能力、高并发吞吐、极低时延、灵活易扩展的新一代AI数据中心网络架构。
需支持千卡级、万卡级GPU集群互联,采用CLOS架构实现弹性可扩展能力。
大模型训练网络带宽向200G、400G、800G不断演进,满足GPU集群海量参数的协同计算。
绕过CPU、OS内核、TCP/IP协议栈等,直接访问对端内存数据,大幅降低通信延迟。
接入层1:1带宽收敛比,利用RMDA、负载均衡技术保证全网智能控制拥塞及吞吐效率。
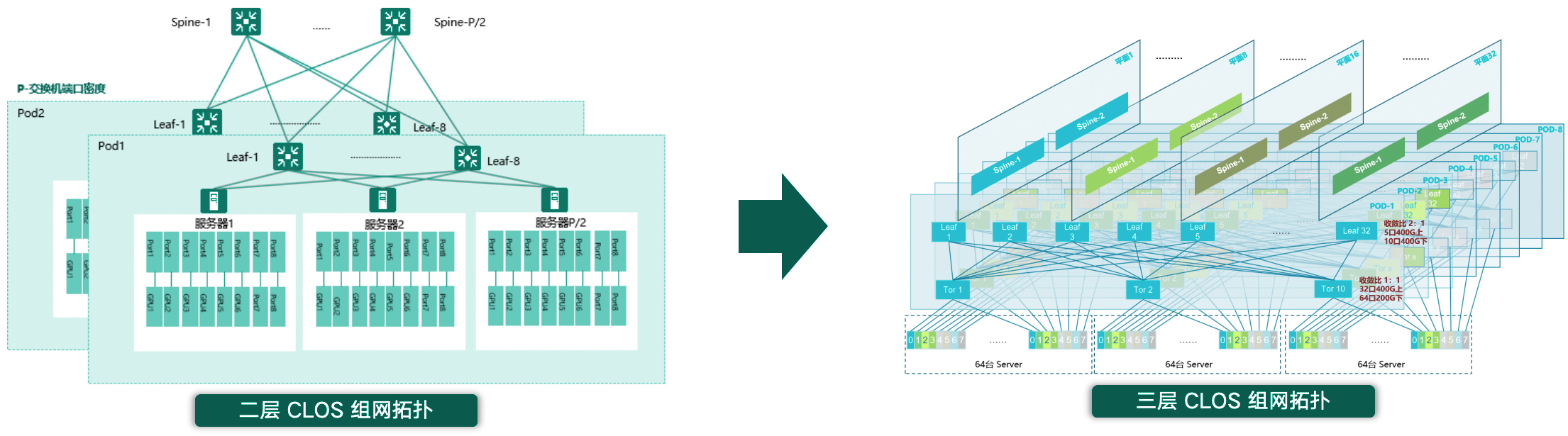
提升通信效率,缩短训练周期:利用RDMA技术旁路内核,消除CPU接入的数据拷贝,将端到端通信时延降低到微秒级,减少GPU计算等待时间,极致计算效率,缩短训练周期。
超高带宽吞吐,突破传统限制:使用400/800G带宽组网,结合RDMA技术,提升网络吞吐性能,保障GPU集群高效计算。
弹性易扩展,开放生态支持:分层CLOS架构支持从千卡到万卡级集群的弹性扩展,可综合预算成本、性能指标、运维习惯等灵活选择RoCEv2/InfiniBand技术路线。





 沪公网安备31011502002642号
沪公网安备31011502002642号
